Badger: 一个纯Go编写的高速KV存储
最近我们使用纯Go语言编写了一套基于LSM Tree的KV存储数据库,能够实现高效的数据存取以及支持持久化。这个数据库主要基于这篇论文:WiscKey paper included in USENIX FAST 2016。这种设计基于SSD进行高度优化,同时将key和value进行拆分存储来最大程度的降低IO的写放大,一并提升SSD的顺序和随机读写性能,我们将它命名为badger。在随机读性能方面,Badger至少是RocksDB 3.5倍的性能。在128B到16KB块大小的数据加载方面,Badger比RocksDB快了0.86-14倍,随着块大小的增加,Badger的性能增加尤为明显。在另一方面,虽然现在Badger在key-value的区间迭代性能方面还有不足,但是还有很大的优化空间。
背景以及动机
关于RocksDB的一些简单介绍
RocksDB基本可以算是市面上最为流行并且性能最好的key-value数据库了。它起源于google内部的SSTable,最早是Bigtable的基础,后来作为LevelDB的产品发布。然后Facebook改进了LevelDB,增加了并发支持并对SSD进行了优化,发布为一个叫做RocksDB的产品。对RocksDB的改进持续了很多年,现在已经使用在Facebook和其他很多公司的线上产品中。 所以如果你需要一款key-value存储的话,RocksDB确实是不二的选择,它已经是一款成熟的产品并且很稳定。但是RocksDB最大的问题是它使用C++编写,如果要在GO的技术栈中使用,必须要引入CGO.
Cgo:权宜之计
在Dgraph,我们从一开始就已经通过Cgo使用RocksDB了,在这个过程中,我们遇到了很多依赖方面的问题。Cgo并不是go,但是如果在C++上有比Go更好的第三方库的话,使用Cgo就成为了一个权宜之计。
但是问题在于,Go的CPU Profiler并不能分析Cgo的调用。Go的Memory Profiler更甚,不要妄想profiler能够详细深入分析Cgo的内存空间栈,它甚至不能检测到Cgo代码的存在。任何Cgo使用的内存空间Go的memory profiler都无法监测。其他工具类似于Go的race dector也不能在Cgo上正常工作。
在Go1.4版本上,pthread_create的问题困扰了我们很久,在Go1.5上又重现了,归咎于bug回归缺陷。如果引入了Cgo,本来轻量级的goroutine就回退化为代价昂贵的pthread线程,因此我们不得不修改数据写入RocksDB的方式来避免生成过多的goroutine。
Cgo同时也有内存泄漏的问题。我们不清楚在Cgo调用的时候到底是谁在拥有并管理着这块内存。Go和C是相互对立的,一个不允许你释放内存,另一个又要申请内存。因此你执行一个Go调用,但是忘记Free内存了,当下不会有什么问题,但是长时间运行以后,你懂的。
Cgo是的我们的代码不可维护,并且引入了不和谐的代码风格。在公司里,没有人愿意去碰和RocksDB连接的Cgo层的代码。
当然,后来在我们的API使用层面我们修复了内存泄漏的问题。实际上,到现在为止,我认为我们已经修复了所有的问题,但是我不能保证。Go的memory profiler是不会告诉你有没有内存泄漏问题的。每次客户抱怨Dgraph的产品占用了太多内存或者因为OOM的原因被杀掉了,我都很紧张这是因为内存泄漏的问题。
艰巨的任务
每当我向别人抱怨Cgo不爽的时候,他们总是建议我只是去改改bug就好了,重写一套和RocksDB性能相仿的KV存储的活实在是太艰巨了,不是很值得。我的组员也是不置可否,我对此也有所怀疑。
这么些年来,我对那些由世界上最聪明的工程师创造出来的技术都心怀敬意,RocksDB就是其中一个。如果我们的Dgraph是用C++编写的话,我会很开心地使用RocksDB。 但是,我真的忍不了丑陋的代码
我也讨厌回归复现的问题。无论付出多大努力,我们都无法保证通过Cgo使用RocksDB不会出现更多问题。我想要干干净净的代码,同时我也期望那些profiler工具能够正常使用。用Go语言从头构建一个KV存储看起来是我们唯一的选择。
我做了一些业界扫描,现存的Go编写的KV存储都无法和RocksDB性能相比。这是成败的决定性问题,不能拿性能换代码整洁,我们两个都需要。
最后,我决定替换我们对RocksDB的依赖。但是这不是Dgraph的首要任务,我们的组员不应该在这个任务上花太多时间。这应该只是一个由我来负责的支线任务。我开始研读B+了LSM树的相关文档以及他们最近的研究成果,同时详细研究了WiscKey的论文。这篇论文给了我很大的启发,我决定从Dgraph的核心开发任务中抽出一个月的时间来构建Badger。
实际上并不是像我想象的这样发展的。我不可能完全脱离Dgraph一个月的时间。由于我创始人的职责, 我也不可能全职投入编码。Badger是在我们的编码运动会开发出来的,同时也包含我一个组员的兼职投入。开发从1月底开始,现在我认为是一个比较好的时间点来贡献给Go社区让大家来试用了。
LSM树
当我们深入探讨Badger之前,我们先来理解一下KV存储的设计思路。KV存储在数据密集型的应用中扮演着非常重要的角色,包括数据库。KV存储尤其擅长高效的更新操作,定点查询以及区域查询操作。
KV存储有2种流行的实现方式::LSM树和B+树。LSM树的优势在于它前台的写操作都是在内存中完成的,后台的写操作可以保持为顺序的写操作,因此它能实现高吞吐的写入操作。另外,在B+-树上进行的小块的更新操作会引入重复的磁盘随机写,因此在写操作上不可能维持太高的吞吐性能。
为了实现写入操作的高性能,LSM树批量打包KV对并将它们顺序写入磁盘。同时为了高效的查询操作,LSM树在后台会持续的读取,排序并且回写KV对,这个操作就是我们常说的compaction压缩。LSM树会在多个level上进行压缩,每一层都比上一层存储更多的数据,典型的遵循这个公式:size of Li+1 = 10 * size of Li
在某一level中,kv对会被排序后写入到固定大小的文件中。除了0 level,其他每一层中每个文件存储的key值都不会重叠。
每一个level都有最大存储容量。如果Li层的空间填满以后,Li层的数据会合并到下一层的Li+1层中,同时Li层的文件会被删除以腾出空间接收新的数据,数据就按照这样的流程从level 0 流入level 2,3…以此类推。同一个数据在它的生命周期中会写入多次,每一次key值的更新都会出发多次的写操作直至数据最终落地,这个过程就形成了所谓的“写放大”。对于一个7层并具有10x的放大因子的LSM树来说,它会将写操作放大60倍,排除L0有特殊操作以外,L1-L6都会有传导影响。
相反的,从LSM树中读取一个数据,需要检查所有的level层。如果数据在多个层中都存在,那么会提取最靠近Level0 的数据。因此,单一一个key的查询就回导致在多个文件中的频繁的读操作,这就是所谓的“读放大”。WiscKey的论文估计:对于1KB的KV对来说,这个放大值将近336
LSM树本身是围绕HDD传统硬盘来设计的。HDD的随机I/O速率比其顺序IO要慢超过100倍,因此后台进行数据压缩来持续的排序key值同时提供高效的查询是一个不错的权衡。
但是,SSD和HDD从本质上就是不同的。SSD上顺序读和随机读的性能差异并不像HDD上的差异那么大。实际上,SSD顶级产品例如三星960Pro可以提供440K,4KB的随机读性能。因此,LSM树中转化为顺序写来降低了随机读操作的设计对带宽来说是个巨大的浪费,没有什么实际用途。
Badger
Badger是一个简单,高效,持久化的KV存储。受到LevelDB简洁化的影响,我们只设计了Get,Set,Delete和Iterate几个操作,在其上,我们还增加了CompareAndSet和CompareAndDelete这样的原子操作。Badger的目标不是一个数据库,因此没有提供事务,版本控制以及快照功能。这些功能基于Badger都很好自行实现。
Badger将Key和Value的存储进行分离。Key存储在LSM树中,value存储在wal(write-ahead log)中。Keys的总体容量一般来说会比value小,因此这个设计会生成一棵体积小很多的LSM树。当进行数据查询的时候,vlaue的值会直接从SSD盘上的log文件中读取,以便最大利用SSD的随机读性能。
设计指导思想
下面是Badger设计上的一些考量,Badger是什么以及Badger不是什么 * 纯Go语言开发 * 使用了最新的研究成果来构建快速的KV存储 * 简单,傻瓜 * SSD为中心的设计
Key和Value分离
SM树最大的性能损耗来自于其压缩的处理过程。在压缩过程中,多个文件读取到内存中进行排序并写回磁盘。排序对于检索是很关键的,不论对于key的查找还是区间迭代来说都是如此。经过排序后,key的查找只需要在每个level中访问一个文件即可(level 0除外,这一层中需要检查所有的文件).迭代操作会转化为多对个文件的顺序访问。
每个文件都是固定大小来增强缓存的能力。Value通常来说都大于Key。当把value和key一起存储的时候,要压缩的数据的容量会明显地增加。
在Badger的设计中,和key一起存储的只有一个指向vlaue日志中的指针值。Badger后期计划引入delta encoding对key进行编码来继续减小key的体积。假设有16字节的key和16字节的指向value的指针,那么一个单独的64MB的文件可以存储200万个KV对。
写放大
由上所述,Badger生成的LSM树会比RocksDB小很多,由此生成的level的层次数也减少了,相应的用于稳定LSM树的压缩操作也减少了。同时,value的值存储在value日志中,并不会和key的值一起移动。假设有1KB的value和16字节的key,现在每一层的写放大的倍率是:(10*16+1024)/(16+1024)~1.14,减小了很多。
当value的大小增长的时候你就会看到这样设计在性能方面的收益,同时当Badger导入数据的时候所需的时间也会按照倍率减小。
读放大
上面说过,Badger产生的LSM树体积小很多,相比于传统的LSM树来说,每层的文件可以存储更多的key值。因此对于相同数量的数据,Badger需要的level层次数也会降低。一个典型的key的查找会读取level 0的所有文件,然后会在每层读取一个文件直到找到为止,因此在Badger中这就意味着查找一个key需要读取的文件总数减少。一旦key的值被找到,value的值就可以从SSD中的value日志中进行随机读取获得。
此外,在性能测试中,我们发现Badger生成的LSM树非常小,特别适合RAM。对于1KB的value值和75,000,000个22字节的key值来说,整个数据集的大小为72GB。Badger生成的LSM树仅仅只有1.7G,非常容易放置在内存中。这就是为什么Badger的随机key查找的性能是RocksDB的3.5倍,同时Badger的key单独迭代的性能更是吊打RocksDB。
故障恢复
LSM树的更新操作首先都是更新内存中的memtables,一旦填满,memtables会被转换为不可变的memtables,这个不可变的memtables最终会写到磁盘中的level 0层的文件中。
如果Badger崩溃,那么所有最近存储在内从中的更新都会丢失。为了处理这个问题,KV存储会先将更新写入到WAL(write-ahead-log)中,Badger也有WAL,叫做value日志。
和传统的WAL一样,更新的数据写入LSM树之间会先写到value日志中。一旦程序崩溃,Badger会遍历value日志中所有最近的更新,然后将相应的数据写回到LSM树中。
Badger并不会遍历整个value log,相反Badger会存储一个指针到memtable中最近的一个value中。这样最近往磁盘中写如数据的memtable都会有一个value指针,在这个指针之前的数据都已经落盘。因此,我们只需要从这个指针处向前处理数据,将所有的更新数据更新到LSM树中即可完全找回我们的更新数据。
占用空间
RocksDB采用了压缩来减小总体占用的空间。Badger的LSM树比RocksDB小了很多,可以整体载入内存中,因此它不需要做任何的压缩操作。但是value日志的大小会增长的很快,每一个更新操作都会在value日志中记录为一个条目,因此对于同一个key的多次更新操作也会记录多次,占用多个条目空间。
Badger采用了2个措施来处理这种情况。它允许在value日志中对vlaues的值进行压缩,我们并不是将多个KV对绑定在一起进行压缩,而是仅仅单独压缩每一个KV对,这样的方式提供了最好的随机读的性能。客户端可以进行相应配置,当KV的大小超过了某个阈值的时候开启压缩特性,这个默认值为1KB
第二点,Badger对value进行了垃圾回收。垃圾回收会周期性运行,从value日志文件中随机选择100MB的空间进行回收。它会检查如果在后期的log中有新的更新,那么前面明显的旧更新就可以丢弃了。因此,如果一个新的KV对添加到了日志中,那么久的文件就可以丢弃,同时更新LSM书中的最近的value指针。这样做的缺点是,LSM树需要进行额外的操作,因此在导入海量数据的过程中最好不要进行垃圾回收。后期计划增加新的特性,使其在空闲的阶段触发垃圾回收。
硬件成本估算
SSD的成本是越来越便宜,相比于使用内存来存储数据提供LSM树服务来说,SSD的成本基本可以忽略不计。考虑如下的因素: 对于16字节的key+1KB的value值,存储75,000,000个这样的KV对,RocksDB中的LSM树大概需要50GB的空间。Badger的value日志在不压缩的情况下需要74GB的空间,而LSM树需要1.7GB。由此推断如果增长3倍,225,000,000个KV对,RocksDB会占用150GB空间,而Badger的value日志占用222GB,同时包括5.1GB的LSM树。
使用亚马逊AWS US East(Ohio)数据中心的成本如下: 1. 如果想要达到和Badger同样的随机读性能(3.5倍),RocksDB必须要使用r3.4xlarger的虚拟机实例,这个实例提供122GB的内存,每个小时的收费是1.33美元,这样所有的LSM树的数据都可以存储在内存中。 2. Badger可以运行在AWS最便宜的为存储提供的实例中 i3.large,这个实例提供了475GB的NVMe SSD(fio的测试其能达到4KB 100K的IOPS性能),同时提供了15.25GB的内存,每个小时的费用是0.156美元。 3. 这样折算下来,在EC2集群上,Badger比RocksDB要便宜8.5倍 4. 以一年为期,预支付情况下,RocksDB需要支付6182美元而Badger只需要870美元,仍然要便宜7.1倍,相比来说Badger节省了86%的费用
性能测试
测试配置
我们租借了一台亚马逊的AWS服务器,i3.large的实例配置,提供了450GB的NVMe SSD,2个虚拟CPU和15.25GB的内存。这个实例提供了本地的SSD,经过我们使用fio测试,4KB块大小的随机读性能可以稳定在100K的IOPS。 无论对于RocksDB还是Badger来说,我们生成的测试数据集足够庞大,不可能全部放入内存中。如下表:
首先我们测试数据串行一条一条进行载入,不使用并发操作,然后我们记录载入数据所使用的时间和最终数据的大小。对于随机的Get和Iterate操作,我们使用Go的测试集测试3分钟,然后后对于16KB的vlaue值测试1分钟。
所有的代码都托管在这里。所有执行的命令行以及测量方法都记录在这个日志文件。生成的图表和数据在这里
测试结果
我们主要测试4种场景: 1. 数据载入性能 2. 输出数据的大小 3. 随机Key查找的性能(Get) 4. 排序的区间迭代的性能(Iterate)
所有4个测试结果图如下所示:
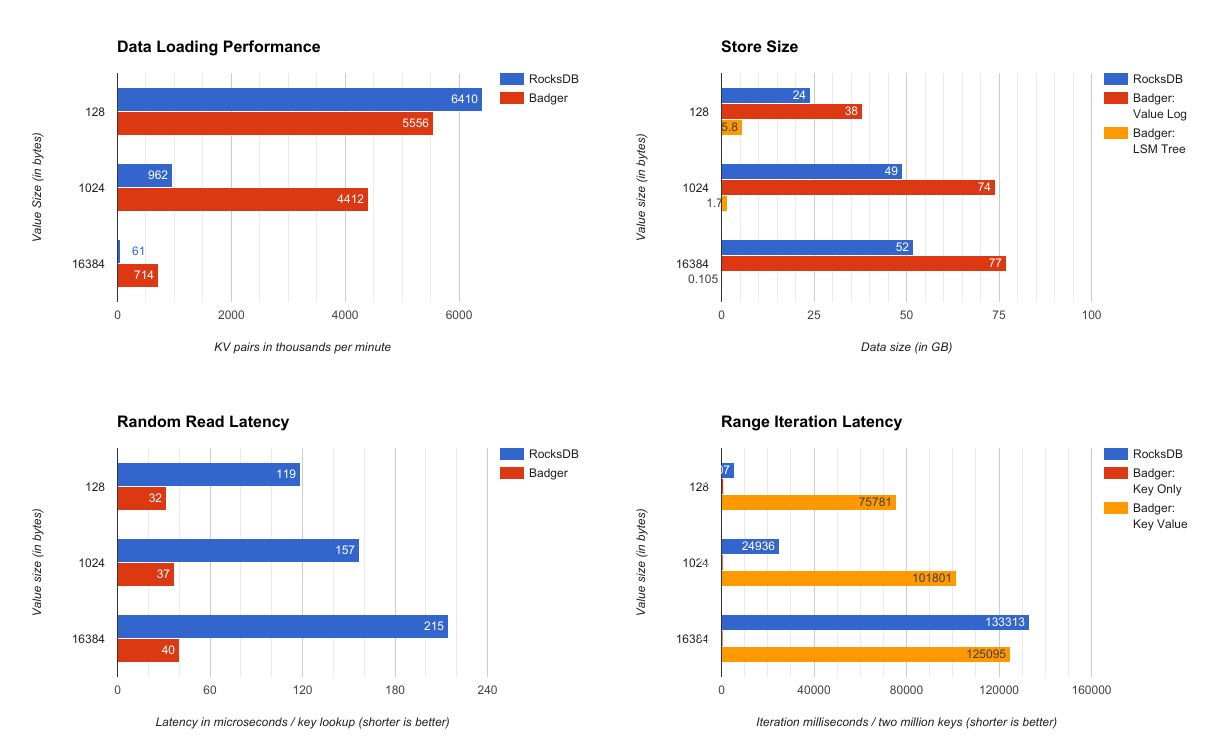
*数据载入性能*:当value的大小增长的时候,Badger KV分离存储的设计对性能的提升尤为明显。对于1KB和16KB的value值,Badger的性能分别是RocksDB的4.5倍和11.7倍。对于小一些的value值,例如16字节的value,Badger可能会慢2-3倍,主要原因还是压缩的性能较低(后期会改进)
*存储空间大小*:Badger生成的LSM树会比较小,但是value日志文件会大一些。LSM树的大小和key的数量等比增长,和value的大小没有关系。因此当value的值从128字节增长到16KB的时候,LSM树的大小呈现减小的趋势。在所有3个场景中,Badger生成的LSM树都非常适合全部载入内存中。
*随机读延迟*:Badger的Get操作的延迟只有RocksDB的18%-27%。这主要归功于我们的设计:Badger的整个LSM树都可以装载进内存,不再需要寻找相应的table,检查布隆顾虑器,获取相应的块获得key的值,然后value的值通过SSD上一个单独的file.pread获取。
相反,RocksDB无法将整棵LSM树载入内存,就算假设其可以将table的索引和布隆过滤器放在内存中,它仍需要从磁盘中获取整个块,并解压进行查询获取KV对(Badger的LSM树很小,以致于并不需要进行压缩)。这个流程明显更加耗时,同时数据获取无法做到局部化,因此cache的命中率也很低。
*区间迭代延迟*:同样从SSD获取value值的情况下,Badger的区间迭代明显比RocksDB慢。这个现象超出了我们的预期,同时我们也很是不理解。可能的原因是Badger需要在SSD上做随机读IOPS的操作,而RocksDB是纯粹的顺序读。但是,就算是使用了能达到100K IOPS的i3.large的虚拟机实例,开启了预取模式后,Badger仍然只是用了部分的磁盘带宽,SSD的带宽并没有用满。因此这个问题需要后期再继续定位解决。 但是在另一方面,Badger的单纯key的区间迭代性能比RocksDB要快很多。这个特性在我们Dgraph中的某些特定场景下很有用,例如我们迭代一组key,进行过滤并获取一小部分key所对应的value值。
未来的一些工作
区间迭代性能优化
Badger里单独Key迭代的性能非常的快,但是当需要查询value的值的时候,性能下降明显。理论上不应该出现这种情况,亚马逊i3.large的虚拟机实例优化后可以达到4k 100,000的随机读性能,这样算下来的话,我们应该能够每秒迭代100K的KV对,也就是每分钟6,000,000的KV对。 但是,当前的Badger对SSD产生的随机读压力完全无法到达理论线速,导致KV的迭代性能大打折扣,这个情况需要深度的分析和优化。
压缩的性能 (compaction和compression的区别是什么?)
相比于RocksDB来说,Badger现在执行压缩操作时速度会慢很多。因此对于value值偏小的数据集来说,Badger在载入数据方面的性能会差一些,这方面也需要更深入的优化工作。
LSM树的压缩
对于value值偏小的数据集来说,Badger的LSM树会比RocksDB生成的LSM树更大一些,因为Badger对LSM树不进行压缩。不过如果需要的话,这个特性很容易就可以添加进来。
B+树
现在的SSD的发展使得B+树成为一个可行的选择,就如WiscKey的论文提到的,现在SSD的随机写的性能提高很快。一个比较有意思的新方向是:结合value日志的方式,把key和value的指针存储在B+-树中。这样设计以后,就不需要使用LSM树的读-排序-合并,顺序写到磁盘的操作了,而是在每个key更新的时候对SSD磁盘进行随机写操作,这样仍然能够获得和LSM树同样的写吞吐性能,同时设计上更为简单了。
结论
我们构建了一个高效的KV存储,可以和市面一线的KV存储性能上相媲美。当前阶段它确实还是有一些缺点的,但是无论是作为数据存储还是构建其他数据库来说,它已经可以作为商业应用软件的坚实平台了。
我们已经在Dgraph内部使用Badger替代对RocksDB的依赖了,它使得我们平台的构建更加容易和快速,同时实现了Dgraph的跨平台特性,使得可嵌入式的Dgraph成为可能。Badger最大的优势在于其高性能的基于纯GO的KV存储设计。好的方面是由于减少了对RAM的依赖,更多依赖于更加快速和便宜的SSD,Badger在Get性能方面4倍于RocksDB,同时潜在节省了86%的亚马逊虚拟主机开销。